Coding is, more or less, solved. That is what people closest to the work are saying now, and I think they are broadly right.
Some context before I go further. I spent the last few months at Turing College on AI Ethics. Roughly 160 hours across fairness, causal interventions, governance, and production deployment. So what follows is not theory.
What is interesting is what is not solved.
What is left in AI
What is left in AI is two things, and only one of them is hard.
The easy part is compute and more efficient engineering. Cheaper inference, longer contexts, faster training, better tooling. The roadmaps are visible. The money will flow. None of it is a research bet anymore.
The hard part is what happens when the model touches a human. Who gets credit. Who gets hired. Who gets flagged for fraud. Who gets a welfare benefit. The moment any of that is automated, the load bearing question stops being engineering quality. It becomes which tradeoff the system made, and on whose behalf.
That is an ethics question, not an engineering one. And I think it is about to be the most interesting topic left in AI.
The Impossibility Theorem
One result from those 160 hours reframed the whole field for me.
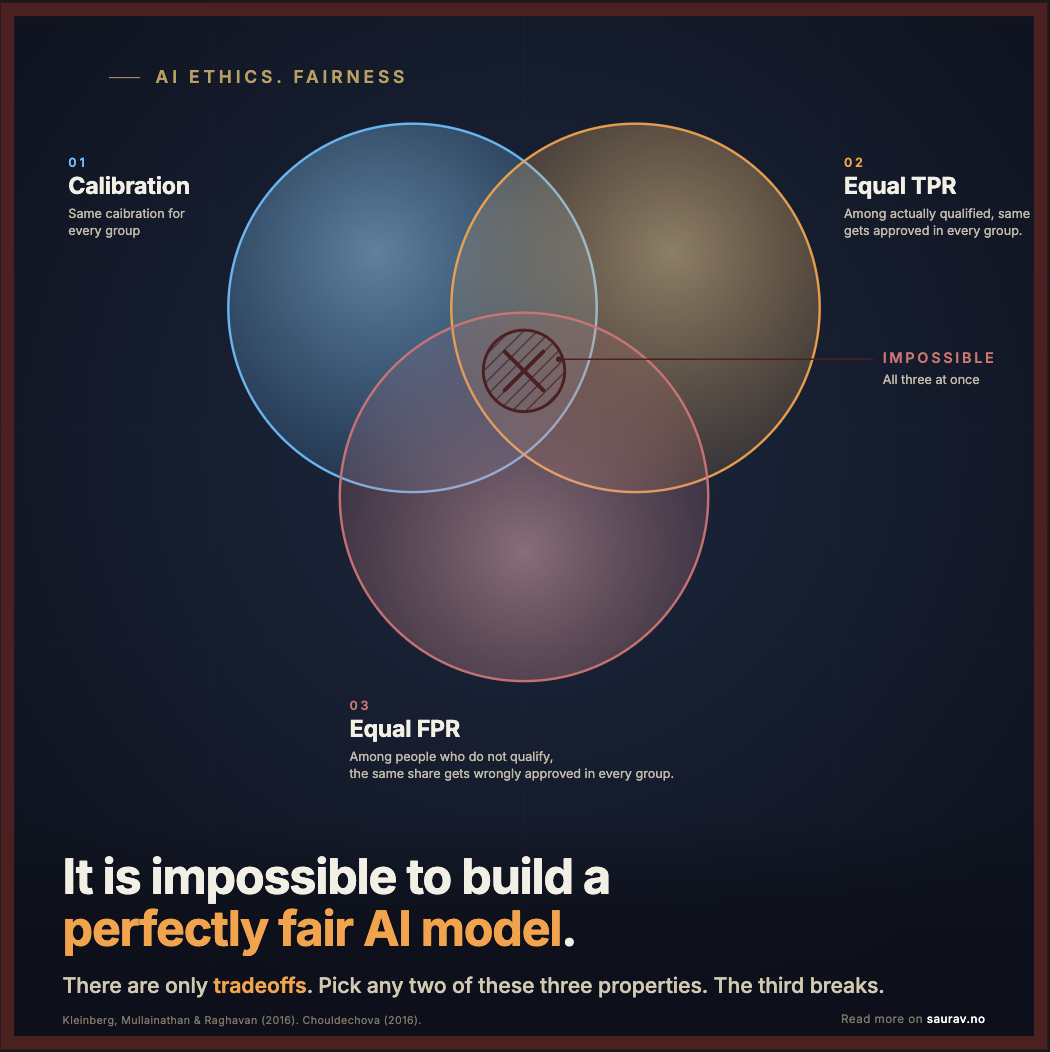
You cannot make a model fair by all definitions simultaneously. It is mathematically impossible.
When base rates differ between groups, and they almost always do, three intuitive properties of fairness cannot coexist:
- Calibration. A score should mean the same thing in every group. When the model says 70%, roughly 70% of those people should actually qualify, whether the group is men or women, young or old. Otherwise the same number is more trustworthy for one group than another.
- Equal true positive rates. Among people who actually qualify, the same share should get approved in every group. Otherwise good candidates are turned away more often in some groups than others.
- Equal false positive rates. Among people who do not qualify, the same share should get wrongly approved in every group. Otherwise the model is more lenient toward some groups than others.
Pick any two. The third breaks.
Kleinberg, Mullainathan, and Raghavan proved it in 2016. Chouldechova proved an equivalent result the same year. Not a tooling limitation. A property of probability.
What this means
So “we optimize for fairness” is a meaningless sentence. You optimize for one definition at the cost of another. The job is to pick which tradeoff to make, and document why.
Fairness is not a problem to solve. It is a tradeoff to govern.
References for this post: Inherent Trade-Offs in the Determination of Risk Scores (Kleinberg et al., 2016) and Chouldechova (2017), Fair Prediction with Disparate Impact, Big Data 5(2).
THis
If you enjoy staying updated on technology, business, and the universe, feel free to read me on Substack.